2021. 11. 18. 15:07ㆍ개인 공부 공간/Python
파이썬을 이용해 데이터프레임을 재구조화 하는 방식은 매우 다양하지만 이번글에서는 pandas에서 제공하는 stack과 unstack을 이용한 방식에 대해 정리하려고 합니다.
stack & unstack
데이터프레임을 일종의 블록이라고 가정하면 stack과 unstack은 마치 블록을 쌓고 분해하는 역할을 하는 함수라고 생각하면 편합니다.
- stack: 데이터프레임(블록)을 높게 쌓는 역할
- unstack: 데이터프레임(블록)을 넓게 분해하는 역할
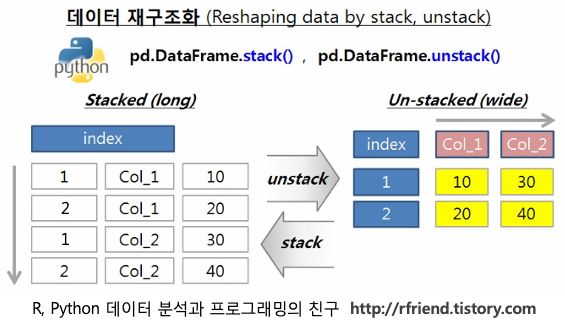
구체적인 예시를 통해 stack과 unstack의 사용법에 대해 설명해보겠습니다.
In [1]:
import pandas as pd
import numpy as np
import seaborn as sns
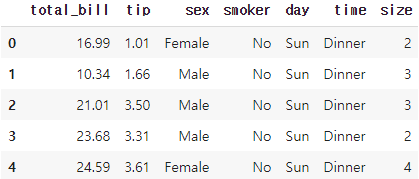
tips = sns.load_dataset('tips')
tips.head()Out [1]:
In [2]:
grouped_tips = tips.groupby(['sex', 'time']).mean()
grouped_tipsOut [2]:
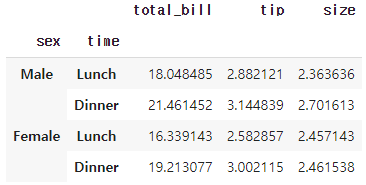
기본으로 제공하는 tips 데이터셋을 불러온 후 sex와 time을 이용해 groupby를 진행했습니다.
stack()을 이용하여 위 grouped_tips를 높게 쌓아보겠습니다.
In [3]:
stacked_tips = grouped_tips.stack() # default: level=-1
stacked_tipsOut [3]:
sex time
Male Lunch total_bill 18.048485
tip 2.882121
size 2.363636
Dinner total_bill 21.461452
tip 3.144839
size 2.701613
Female Lunch total_bill 16.339143
tip 2.582857
size 2.457143
Dinner total_bill 19.213077
tip 3.002115
size 2.461538
dtype: float64grouped_tips는 컬럼 level이 1까지만 존재하기 때문에 level 파라미터에 -2를 입력할 경우 다음과 같은 에러가 발생합니다.
IndexError: Too many levels: Index has only 1 level, -2 is not a valid level number
stack()을 적용한 stacked_tips는 level이 3개 있는 MultiIndex 입니다. 이럴 경우 다시 unstack() 파라미터 level을 각각 -1, 0, 1로 둘 때 각각 어떤 level이 컬럼으로 이동하는지 확인하시기 바랍니다.
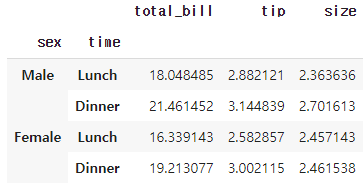
In [4]:
stacked_tips.unstack(level=-1) # defualt = -1Out [4]:
In [5]:
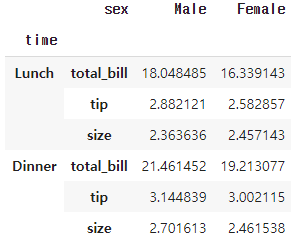
stacked_tips.unstack(level=0)Out [5]:
In [6]:
stacked_tips.unstack(level=1)Out [6]:
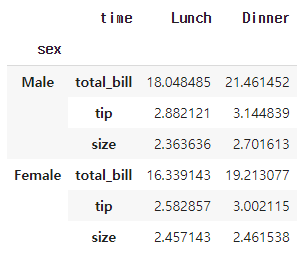
unstack()의 level을 -1로 두면 stack() 적용 이전과 동일해지고 0과 1인 경우 각각 sex와 time이 컬럼으로 이동합니다. level을 3으로 두면 total_bill, tip, size가 컬럼으로 이동하며 -1과 동일한 결과를 리턴하고 4이상 부터는 더 이상의 level이 존재하지 않기때문에 에러가 발생합니다.
References
'개인 공부 공간 > Python' 카테고리의 다른 글
| [python] pymysql을 이용하여 INSERT하기 (1) | 2021.10.04 |
|---|